
What Teens, Screens and Digitally Divided Attention Spans Mean for Learning [Infographic] | The LAMP

Something unsurprising happens when you task two star designers to curate a catalog of their favorite objects: You end up with a collection of ridiculously well-designed products. This is exactly what happened when Sotheby’s tapped Jony Ive and Marc Newson to pull together a list of goods to be auctioned off at the (RED) Auction, which is raising money for the Global Fund to Fight AIDS, Tuberculosis and Malaria.
Read: 18 of the Best Designs of All Time, Picked by Jony Ive and Marc Newson | Wired Design | Wired.com
Amanda Lenhart presented nine major themes from the Project’s five-report series on Teens and Online Privacy. In a talk delivered to the Family Online Safety Institute’s annual conference on November 7th, Amanda examined youth’s social media diversification and sharing practices, privacy choices, and the ways that youth concepts of privacy differ from adults.
Interested in creating a Makerspace in your library? This program will discuss what a Makerspace is, how libraries of all types create and share Makerspaces with library customers and the community and feedback from users. Libraries are a much needed and often used third space, which are ideal for community Makerspaces to collaborate and encourage creativity among all users. There will be gadgets, hands-on demos and group discussion on the nuts & bolts necessary for Makerspace in the library as well as what products should be found in successful Makerspaces. Gordon Wyant will share how his library successfully wrote a grant for a 3D printer, and Michael Sauers will demo a range of new gadgets including a Raspberry Pi and LibraryBox.
Presenters: Marcia Dority Baker, University of Nebraska College of Law Library, Lincoln; Michael Sauers, Nebraska Library Commission; Gordon Wyant, Bellevue Public Library.
via Tinkers, Printers & Makers: Makerspaces in the Library | The Travelin’ Librarian
Related:
For many companies in Silicon Valley, it’s fairly easy to find, train, and evaluate technical talent — for the most part, it’s easy to determine and quantify how well a person codes. But evaluating and training non-technical personnel is something many struggle with. To help change this, a new school called Tradecraft has emerged to help teach those seeking UX, growth, and sales positions the skills they need to succeed in the tech world.
Tradecraft was founded by Russ Klusas and Misha Chellam, who believe it (or something like it) is necessary to teach necessary skills to non-technical tech workers.
Read: Tradecraft Launches A School For Teaching Non-Technical Skills To Tech Workers | TechCrunch.
Full Post
Google may be the dominant search engine, but it’s far from ideal. One major problem: How do you search for things you don’t know exist?
Using Google’s own experimental algorithms, a graduate student may have build a solution: a search engine that allows you to add and subtract search terms for far more intuitive results.
The new search engine, ThisPlusThat.Me, similarly looks for context clues among the terms. For instance: Entering the arithmetic search “Paris – France + Italy” gives the top result as “Rome,” but if I search the same thing in Google, I’ll get directions between Paris and Italy, restaurants in France and Italy, and a depressing Yahoo Answers of whether Italy is in Paris (or vice versa). “Rome,” on the other hand, is an association you, a human, would make (I wantThis, without That but including Those)–and the engine makes that decision based on each answer’s semantic value compared to your search.
Until now, search has been stuck in a paradigm of literal matching, unable to break into conceptual associations and guessing what you mean when you search. There’s a reason Amazon and Netflix have scored points for their item suggestions: They’re thinking how you think.
The engine, created by Astrophysics PhD candidate Christopher Moody, uses Google’s own open-source word2vec algorithm research to take the terms you searched for and ranks the query results by relevance, just like a normal search–except the rankings are based on “vector distances” that have a lot more human sense. So in the above example, other results could have been, say, Napoleon or wine–both have ties with the above search terms, but within the context of City – Country + Other Country, Rome is the vector that has the closest “distance.”
All the word2vec algorithm needs is an appropriate corpus of data to build its word relations on: Moody used Wikipedia’s corpus as a vocabulary and relational base–an obvious advantage in size, but it also had the added benefit of “canonicalizing” terms (is it Paris the city, or Paris from the Trojan War? In Wikipedia, the first is “Paris” and the second “Paris_(mythology).” But millions of search-and-replaces in Wiki’s 42 GB of text was intensive, so Moody used Hadoop’s Map functions to fan those search-and-replaces to several nodes.

A search query then spits out an 8 GB table of vectors with varying distances; Moody tried out a few data search systems before settling on Google’s Numexpr to find the term with the closest vector distance.
via This Grad Student Hacked Semantic Search To Be Better Than Google | Co.Labs | code + community.
The PlayStation 4 is finally available. Here’s the quick skinny on what you need to know about Sony’s just-released game console.
Read: PS4: Everything you need to know | Reviews – Games and Gear | CNET Reviews.
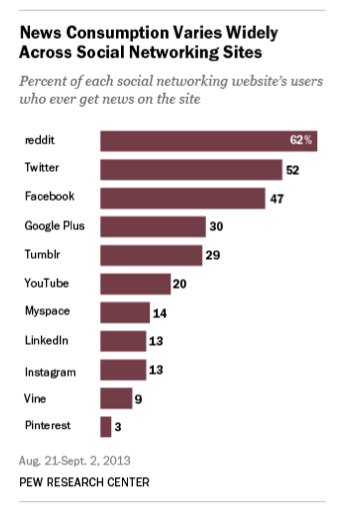
The Pew Research Center is today releasing comparative numbers looking at how U.S. adults use social networking sites to read news (a follow-on from earlier research focusing on two specific sites, Facebook and Twitter).
This is significant for a couple of reasons. Social media sites have become a key component of how many news organizations today are looking to reach consumers as old-media forms like printed editions continue to decline. In turn, social media sites are turning news a way of attracting more eyeballs to improve their own ad-based businesses. That is to say, news and social media are dancing partners that are still working out how to move in the same direction without stepping on each other’s feet, and this survey is one indicator of how well the public is receiving that.
Read more and see all the charts: Pew Social Media Study: 30% Of The U.S. Gets News Via Facebook; Reddit Has The Most News-Hungry Regular Users | TechCrunch.
Facebook just tried to spend $3 billion on a 20-person company that lets you send disappearing photos. At least, that’s the word from The Wall Street Journal, a rather trustworthy source.
According to the paper, SnapChat rejected the offer. But the amazing thing is that Facebook would offer that much money in the first place. SnapChat has no revenues, and its collection of users — however many there are — is puny when you consider that Facebook reaches over 1.2 billion people around the world. Across the internet, so many people are asking themselves: Why on earth would Facebook offer so much for this tiny company?
Read more: Why Facebook Would Pay $3 Billion for Snapchat (And Why It Shouldn’t) | Wired Business | Wired.com.
Full Post
Eight years after a group of authors and publishers sued Google for scanning more than 20 million library books without the permission of rights holders, a federal judge has ruled that the web giant’s sweeping book project stayed within the bounds of U.S. copyright law.
On Thursday morning, U.S. Circuit Judge Denny Chin dismissed a lawsuit from the Author Guild, ruling that Google’s book scans constituted fair use under the law. Though Google scanned those 20 million books in full and built a web service, Google Books, that lets anyone search the digital texts, users can only view “snippets” of a book if the right holder hasn’t given approval.
“In my view, Google Books provides significant public benefits,” the ruling reads. “It advances the progress of the arts and sciences, while maintaining respectful consideration for the rights of authors and other creative individuals, and without adversely impacting the rights of copyright holders.”
In a statement sent to WIRED, a Google spokesperson said the company was “absolutely delighted” with the ruling. “As we have long said, Google Books is in compliance with copyright law and acts like a card catalog for the digital age giving users the ability to find books to buy or borrow.”
Michael Boni, a partner with Boni & Zack, the law firm representing the Authors Guild, did not immediately respond to a phone message seeking comment. Nor did the Author’s Guild. But the Guild has told other news outlets it will appeal the decision.
“We disagree with and are disappointed by the court’s decision today. This case presents a fundamental challenge to copyright that merits review by a higher court,” reads a statement sent to GigaOm. “Google made unauthorized digital editions of nearly all of the world’s valuable copyright-protected literature and profits from displaying those works. In our view, such mass digitization and exploitation far exceeds the bounds of the fair use defense.”
The ruling comes two years after Judge Chin rejected a $125 million settlement between Google, the Author’s Guild, and the Association of American Publishers, which was also part of the original lawsuit against the web giant. After complaints over the settlement from outside organizations such as the Internet Archive and Google rivals such as Microsoft, Chin ruled the deal would give Google a de facto monopoly over so-called “orphan books,” scanned texts whose rights holders had not come forward to claim their share of the revenues Google would make from its book scanning endeavor.
A year after this ruling, the publishers agreed to another settlement with Google, and this one was not subject to approval from the court. But Chin allowed the case to continue as a class action, but an appeals court reversed this decision and told Chin to rule on the copyright issue.
Though Google limits how much book text you can view online — and though it doesn’t display ads on pages describing books it does not have rights to, the company, as the court explained, can still use its service to draw people to its websites and make money in other ways. But this commercial gain doesn’t necessarily mean copy infringement. Google Books, the judge ruled, doesn’t “negatively impact the market for books.”
On the contrary, Chin said, Google Books feeds the market for books. “A reasonable factfinder could only find that Google Books enhances the sales of books to the benefit of copyright holders,” the ruling reads. “Google Books provides a way for authors’ works to become noticed, much like traditional in-store book displays.”
via 8 Years Later, Google’s Book Scanning Crusade Ruled ‘Fair Use’ | Wired Business | Wired.com.
